ML Incubation Palo Alto

Fredrick Chew
Camille Girabawe
Joanna Li
Hameesh Manadath
Alexander Schaefer
28.07.2017
Machine Learning - Approaches
-
Supervised Learning
Learning with a labeled training set
-
Unsupervised Learning
Discovering patterns on unlabeled data
-
Reinforcement Learning
Learning based on reward/feedback and inputs/actions into the environmental
What is Reinforcement Learning

System/Agent

Environment
OBSERVATIONS
ACTIONS
From [numbers] to Actions
- Like DeepMind, we use a gaming environment for experimentation.
- DeepMind's Atari code is overwhelming to experiment. We use REINFORCEjs (on JS Games)
- Goal is to simply maximized score
- One system/algo that learns to operate
on 3 different environments.

JS Pong
Environment State:
- pong coord X, Y
- paddle's Y
Action Space:
- Move up
- Move down
- Stop
Goal/Rewards:
- Lose a ball: -1
- Score a goal: +1
- Zero reward
What to cache ?
HOT
COLD
Workload: 1, 2, 0, 4, 3, 5 ...1, 2, 0, 4...
fast access
reward = +10
slow access
reward = -10
data movement
reward = -1
Environment State:
- Last query data element
Emulator inspired by Data-Aging
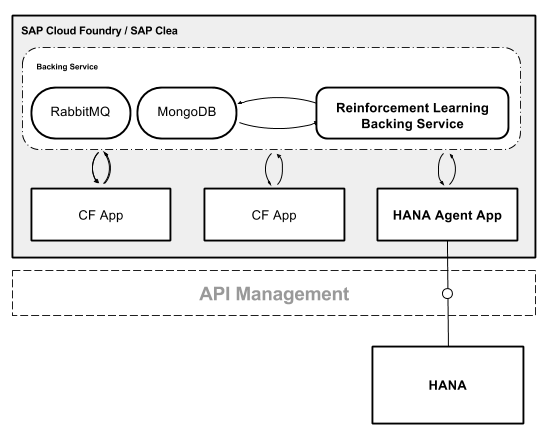
Tuning HANA's parameter
Single Query Template: analytical query that is not cached
Adjusting HANA's max_concurrency based on predicted workload as a POC
Environment State:
- current max_concurrency# [1 to 63]
Action Space:
- increase cpu by 1 core
- do nothing
- decrease cpu by 1 core
Goal/Rewards:
- punish agent if it violates CPU boundary:
- - 0.2 x
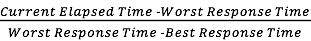
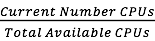
Learning based on Rewards/Goals
-
Dopamine the reward signal for the human brain
- Intuition: RL mimics this process
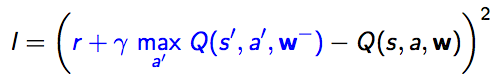
DQN Formula:
Key take away: We are formalize "Learning through failures" via rewarding signals
Be careful on how you reward !:
Unintended consequences may happen. Next game show this effect
RL Hyerparameters
-
Epsilon: Exploration vs Exploitation
- Alpha: Learning rate (NN)
- Gamma: Greediness
Just one year ago
Google DeepMind published a paper in 2015 Nature
Human-level control through deep reinforcement learning
Google bought DeepMind for 500 million
JS Breakout
Environment State:
- ball's X,Y
- paddle's X
Action Space:
- Move left
- Move right
- Stop
Goal/Rewards:
- paddle missed ball: -1
- paddle bounce ball: +1
- zero reward for rest
Agent learnt a nice strategy to maximized reward with least movement
ML Incubation Palo Alto
Pong
BreakOut
What2Cache
ReinforceJS
fredrick.chew@sap.com
Demos: